BAKU: An Efficient Transformer for Multi-Task Policy Learning
Abstract
Training generalist agents capable of solving diverse tasks is challenging, often requiring large datasets of expert demonstrations. This is particularly problematic in robotics, where each data point requires physical execution of actions in the real world. Thus, there is a pressing need for architectures that can maximally absorb available training data. In this work, we present BAKU, a simple transformer architecture that enables efficient learning of multitask robot policies. BAKU builds upon recent advancements in offline imitation learning and meticulously combines observation trunks, action chunking, multi-sensory observations, and action heads to substantially improve upon prior work. Our experiments on 129 simulated tasks9 across LIBERO, Meta-World suite, and the Deepmind Control suite exhibit an overall 18% absolute improvement over RT-1 and MT-ACT, with a 36% absolute improvement on the harder LIBERO benchmark. On 30 real-world manipulation tasks, given an average of just 17 demonstrations per task, BAKU achieves a 91% success rate.
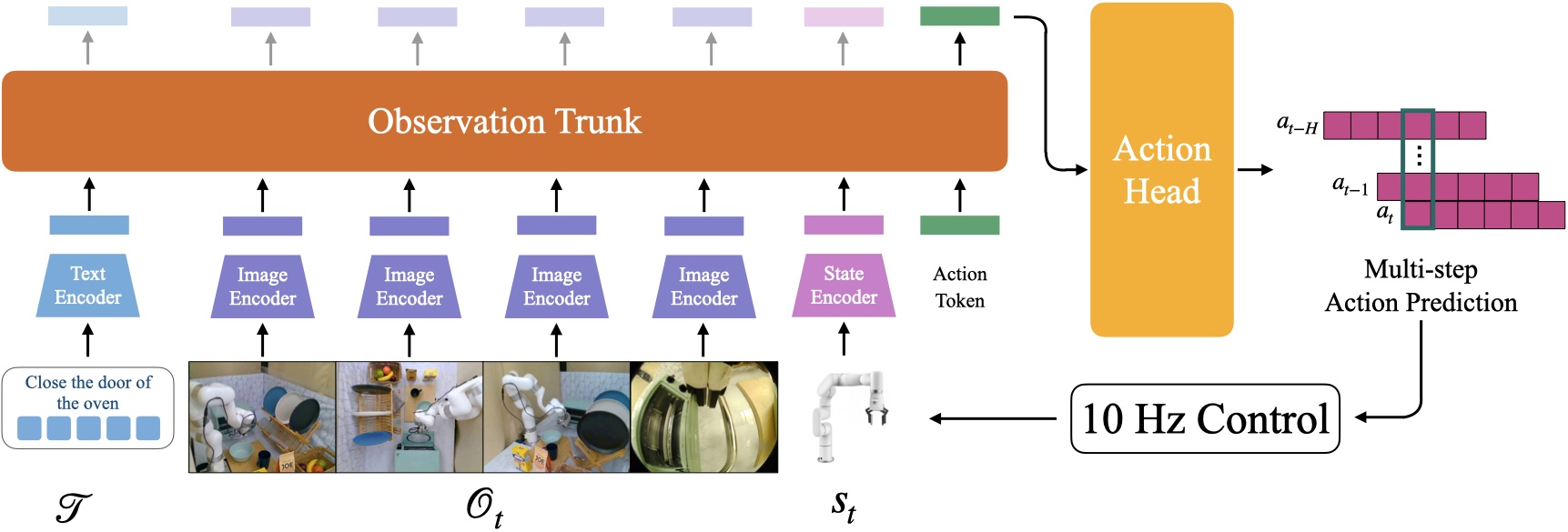
Proposed Architecture
BAKU is broken down into modality-specific sensory encoders, an observation trunk, and an action head predicting a chunk of actions. BAKU takes as input observations from multiple camera views, robot proprioceptive state and a task instruction and enables performing closed-loop control at 10Hz in our real world experiments on the xArm.
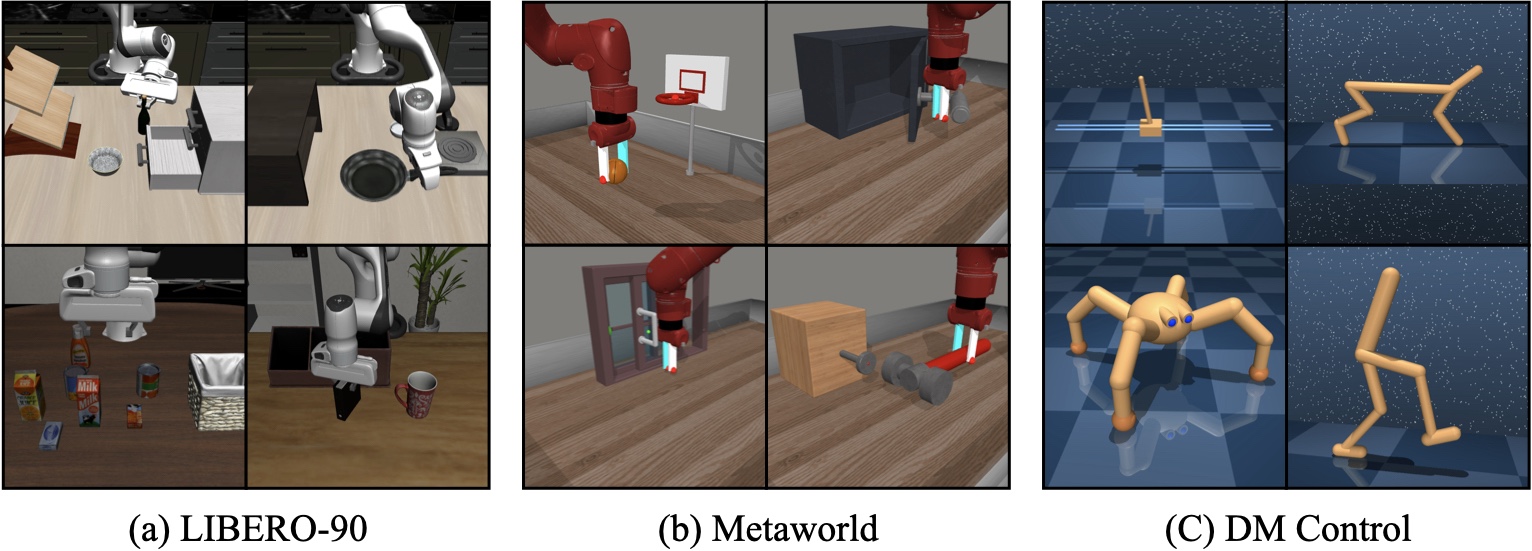
Simulated environments
BAKU is evaluated on 3 simulated benchmarks - LIBERO, Meta-World, and DM Control Suite.
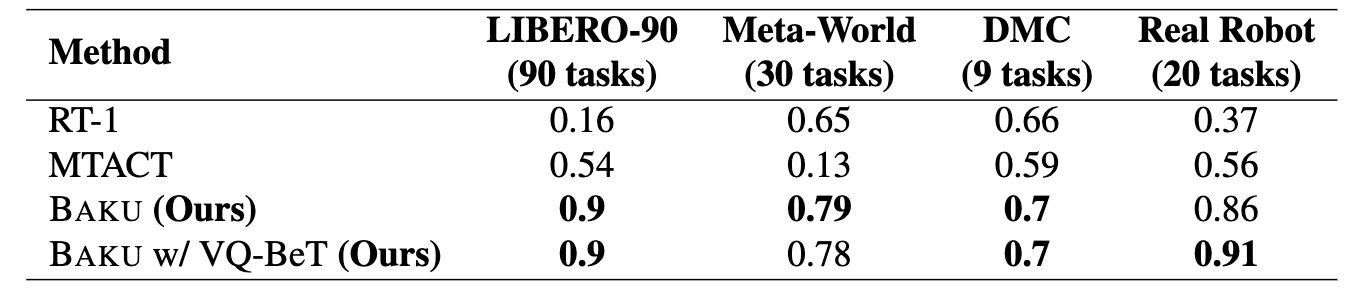
Multi-task Performance
BAKU is evaluated on 129 tasks across 3 simulated benchmarks - LIBERO, Meta-World, and DM Control Suite. BAKU achieves an overall 18% absolute improvement over RT-1 and MT-ACT, with a 36% absolute improvement on the harder LIBERO benchmark. On our real-world xArm multi-task kitchen environment on 30 tasks, BAKU achieves a 91% success rate, outperforming the strongest baseline by 35%.
Real World Rollouts
Utilizing BAKU, we execute a total of 30 tasks on our xArm multi-task kitchen environment. BAKU with an average of just 17 demonstrations per task achieves a 91% success rate with a VQ-BeT, a 35% improvement over the strongest baseline. All videos are played at 1X speed.Successful Rollouts
Failed Rollouts
BAKU on Long Horizon Tasks
We evaluate BAKU on 5 long-horizon tasks in our xArm multi-task kitchen environment. BAKU with an average of just 19 demonstrations per task achieves an 84% success rate, a 20% improvement over our strongest baseline, MT-ACT. All videos are played at 1X speed.Long-horizon Rollouts
What matter for multi-task policy learning?
We perform an extensive ablation study to understand the importance of different components for multi-task policy learning.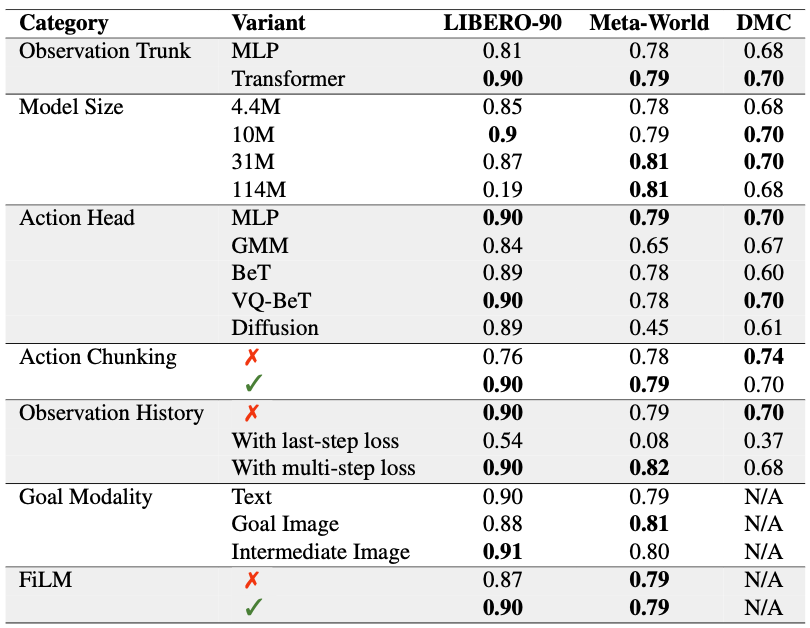
Bibtex
@article{haldar2024baku,
title={BAKU: An Efficient Transformer for Multi-Task Policy Learning},
author={Haldar, Siddhant and Peng, Zhuoran and Pinto, Lerrel},
journal={arXiv preprint arXiv:2406.07539},
year={2024}
}